Application programmed in Java, with libraries organized in modules.
The extraction of games, its most outstanding function, is based on a parser that combines a lexical analyzer with a syntactic analyzer
The initial version of this parser enabled the extraction of games in algebraic notation across multiple languages
As of version v1.26, extracting games using algebraic notation of the pieces is permitted
This new function was developed by enhancing the existing game parser to include a layer that translates piece images into their corresponding initials.
An image-to-initials translator has been implemented using the nearest neighbor algorithm with K = 1
The translator chooses the closest option based on an error measure from the labeled examples it has set.
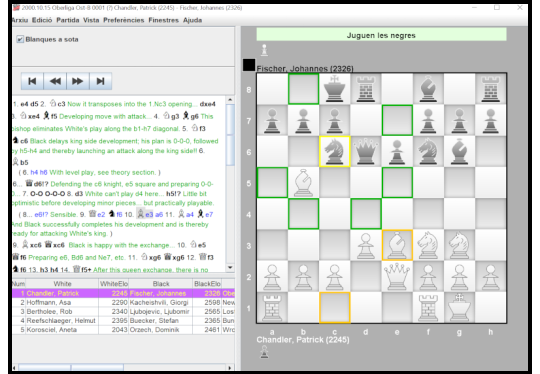
Another interesting feature introduced in version 1.20 is position recognition. The application attempts to determine the position's FEN string by analyzing an image of the chessboard.
This functionality is based on theories from an IEEE article that I purchased for reference:
- It aims to determine the positions of the squares on the chessboard by detecting their sides.
- If successful, the app traverses all the squares and tries to recognize the pieces in each square. The app will try to identify the piece with the nearest neighbor algorithm if a square is empty.
- If all the squares are successfully identified, it is assumed that the board is also identified successfully.
- If the user cannot identify all the squares, the application will show them the board with the recognized squares and asked to complete it for more examples to identify the board entirely.
When the games are extracted from a PDF, the board reader is self-trained using images of known positions, which help it learn to identify squares with pieces
Version 1.20 introduces a new feature that extracts game metadata, including player names, ELO ratings, dates, and locations.
This feature utilizes a system of regular expressions that accommodates various metadata formats I encountered during testing.
Another interesting feature added in v1.20 is the option to connect to UCI-like engines, such as Stockfish.
I developed a generic engine configurator for this feature. It reads the engine configuration upon connection and generates a form for users to modify the engine options.
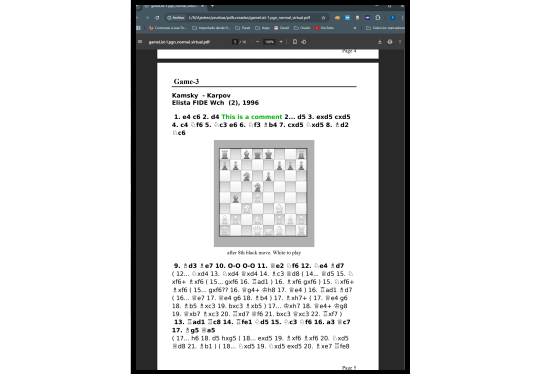
Since version 1.30, the application includes a new binary that allows you to create a PDF from a .pgn file, with two options: a graphical interface application, or a command-line application option, to automate the process.